Modelado conceptual de bases de datos
Clasificación según el modelo de datos
Cuando hablamos de bases de datos, una de las formas más comunes de clasificarlas es según el modelo de datos que utilizan. El modelo de datos define cómo se organizan, almacenan y manipulan los datos dentro de la base de datos. A continuación, vamos a explorar tres de los modelos más comunes: relacional, orientado a objetos y NoSQL.
1. Bases de Datos Relacionales RDBMS
Descripción
Las bases de datos relacionales son el tipo más común y ampliamente utilizado en el mundo. En este modelo, los datos se organizan en tablas que se componen de filas y columnas. Cada tabla representa una entidad (por ejemplo, "Clientes" o "Productos") y cada fila de la tabla es un registro individual que representa una instancia de esa entidad. Las columnas, por otro lado, representan los atributos de la entidad (como "Nombre", "Dirección", "Precio", etc.).
Una característica clave de las bases de datos relacionales es que las tablas pueden estar relacionadas entre sí mediante claves primarias y claves ajenas (foráneas). Esto permite que los datos se conecten de manera lógica, lo que facilita su manejo y consulta.
Ventajas
- Estructura bien definida: Los datos se organizan de manera clara y estructurada.
- Integridad de datos: Las relaciones y restricciones aseguran que los datos sean consistentes y correctos.
- Uso extendido: Existe una amplia gama de herramientas y conocimientos disponibles para trabajar con bases de datos relacionales.
Ejemplos de uso
- Sistemas de gestión empresarial (ERP)
- Aplicaciones bancarias
- Plataformas de comercio electrónico

2. Bases de Datos Orientadas a Objetos (SGBD Objeto-Relacional)
Descripción
Las bases de datos orientadas a objetos combinan los principios de la programación orientada a objetos con el almacenamiento de datos. En lugar de organizar los datos en tablas, como en las bases de datos relacionales, aquí los datos se almacenan en objetos. Cada objeto contiene tanto datos como las operaciones que se pueden realizar sobre esos datos (métodos).
Este modelo es especialmente útil cuando los datos que se manejan son complejos y están estrechamente relacionados con las operaciones que se realizarán sobre ellos. Por ejemplo, si tienes un sistema que maneja gráficos, los objetos pueden representar diferentes formas geométricas, con propiedades (como color o tamaño) y métodos (como rotar o escalar).
Ventajas
- Mayor alineación con la programación orientada a objetos: Facilita el desarrollo de aplicaciones en lenguajes orientados a objetos.
- Manejo de datos complejos: Es ideal para datos que no encajan bien en un formato tabular simple.
- Reutilización de código: Los objetos y sus métodos se pueden reutilizar en diferentes partes de la aplicación.
Ejemplos de uso
- Sistemas de diseño asistido por computadora (CAD)
- Sistemas de gestión de multimedia
- Aplicaciones científicas
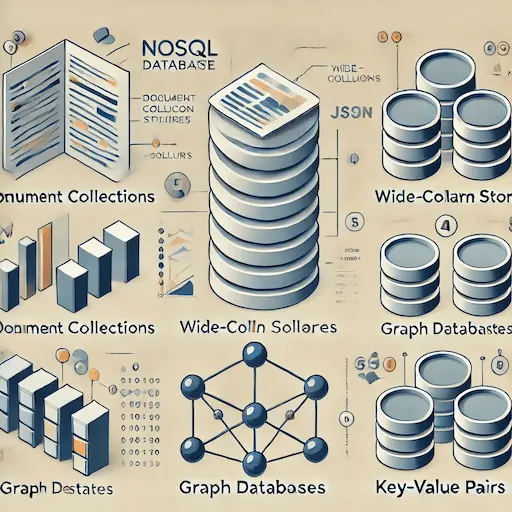
3. Bases de Datos NoSQL (SGBD No Relacional)
Descripción
Las bases de datos NoSQL son una categoría amplia que incluye varios tipos de bases de datos no relacionales. A diferencia de las bases de datos relacionales, NoSQL está diseñado para manejar grandes volúmenes de datos no estructurados o semi-estructurados. Estas bases de datos son altamente escalables y se utilizan a menudo en aplicaciones que requieren un rendimiento rápido y flexible.
Hay varios tipos de bases de datos NoSQL, cada una optimizada para diferentes necesidades:
- Bases de datos de clave-valor: Almacenan datos como un par clave-valor, donde cada clave es única y se asocia a un valor. Son simples y rápidas, ideales para casos como cachés o configuraciones.
- Bases de datos de documentos: Almacenan datos en documentos, que son objetos complejos, generalmente en formato JSON o BSON. Este tipo es útil para almacenar datos que varían en estructura, como catálogos de productos.
- Bases de datos de columnas: Almacenan datos en columnas en lugar de filas. Esto es útil para consultas analíticas rápidas sobre grandes cantidades de datos.
- Bases de datos de grafos: Especializadas en relaciones complejas entre datos, donde los nodos representan entidades y las aristas representan las relaciones entre ellas. Se usan en redes sociales o recomendaciones.
Ventajas
- Escalabilidad: Pueden manejar grandes cantidades de datos y usuarios distribuidos geográficamente.
- Flexibilidad: Adecuadas para datos que no se ajustan bien a un esquema fijo.
- Alto rendimiento: Diseñadas para ser rápidas, especialmente en operaciones de lectura y escritura.
Ejemplos de uso
- Redes sociales
- Aplicaciones de análisis de datos
- Aplicaciones móviles y web escalables
4. SGBD en Memoria (In-Memory)
Almacenan los datos directamente en la memoria RAM para un acceso mucho más rápido en lugar de almacenarlos en disco. Son útiles para aplicaciones que requieren un alto rendimiento. Ejemplo: Redis, Memcached.
Clasificación según la ubicación de la información
Además de clasificarse por el modelo de datos, las bases de datos también se pueden clasificar según la ubicación de la información. Esta clasificación se basa en cómo y dónde se almacenan y gestionan los datos. Principalmente, existen dos tipos: bases de datos centralizadas y bases de datos distribuidas.
1. Bases de Datos Centralizadas
Descripción
Una base de datos centralizada es aquella en la que todos los datos se almacenan en un solo lugar. Este lugar puede ser un servidor o un conjunto de servidores ubicados en una única ubicación física. Todos los usuarios y aplicaciones que necesitan acceder a la información se conectan a este único punto central.
Características
- Único punto de control: Dado que todos los datos se encuentran en un solo lugar, es más fácil gestionar y mantener la base de datos. Las políticas de seguridad, el control de acceso y las copias de seguridad se realizan desde un único servidor.
- Facilidad de administración: Con la información centralizada, el equipo de TI puede enfocarse en administrar un único sistema, lo que simplifica las tareas de mantenimiento y actualización.
- Menor complejidad en la sincronización: No es necesario preocuparse por sincronizar datos entre múltiples ubicaciones, ya que toda la información reside en un solo lugar.
Limitaciones
- Riesgo de fallo único: Si el servidor central falla, toda la base de datos queda inaccesible, lo que puede ser crítico para operaciones que dependen de acceso continuo a la información.
- Problemas de escalabilidad: A medida que crece el número de usuarios o la cantidad de datos, el sistema centralizado puede volverse lento o ineficiente, ya que todas las solicitudes de datos pasan por un solo servidor.
- Latencia para usuarios remotos: Los usuarios ubicados lejos del servidor central pueden experimentar latencias más altas al acceder a la base de datos.
Ejemplos de uso
- Sistemas de gestión en pequeñas y medianas empresas: Donde la cantidad de datos y el número de usuarios no justifica la necesidad de un sistema distribuido.
- Aplicaciones internas de una organización: Donde todos los empleados están ubicados en la misma oficina o sede.

2. Bases de Datos Distribuidas
Descripción
Una base de datos distribuida es aquella en la que los datos se almacenan en varios lugares diferentes. Estos lugares pueden ser diferentes servidores en distintas ubicaciones geográficas. A pesar de estar físicamente dispersos, los datos en una base de datos distribuida se gestionan y se presentan como si estuvieran en un solo lugar.
Características
- Distribución geográfica: Los datos pueden estar repartidos en varios servidores ubicados en diferentes partes del mundo. Esto permite a los usuarios acceder a la información desde la ubicación más cercana, reduciendo la latencia.
- Alta disponibilidad y tolerancia a fallos: Si uno de los servidores falla, los datos siguen siendo accesibles desde otros servidores en la red. Esto reduce el riesgo de que toda la base de datos quede inaccesible debido a un solo fallo.
- Escalabilidad: Es más fácil escalar una base de datos distribuida añadiendo más servidores en diferentes ubicaciones para manejar un mayor volumen de datos o usuarios.
Limitaciones
- Complejidad de administración: Gestionar una base de datos distribuida es más complejo, ya que implica sincronizar datos entre múltiples servidores, asegurar la consistencia de la información y gestionar la red que conecta estos servidores.
- Consistencia de datos: Mantener los datos sincronizados y consistentes en todos los servidores puede ser un desafío, especialmente si la red es lenta o los servidores están muy dispersos.
- Costos elevados: Los costos asociados con la infraestructura, la red y la administración de una base de datos distribuida suelen ser mayores que los de una base de datos centralizada.
Ejemplos de uso
- Grandes corporaciones y servicios globales: Como bancos, redes sociales y servicios de streaming, que necesitan manejar grandes volúmenes de datos y usuarios en diferentes partes del mundo.
- Aplicaciones que requieren alta disponibilidad: Donde el acceso a los datos debe estar garantizado 24/7, incluso en caso de fallos en parte de la infraestructura.

- Loading...